
In today’s digital landscape, search engines play a crucial role in how users find your website. One essential tool to help guide search engines on what content they should (or should not) crawl is the robots.txt file. This file is a must-have for webmasters and SEO professionals who want better control over how their site is indexed and discovered by search engines. But what exactly is robots.txt, and how do you set it up properly? Let’s dive in.
What is Robots.txt?
Robots.txt is a simple text file stored in your website’s root directory that gives instructions to web crawlers or bots (such as Googlebot). These crawlers read this file when they visit your site, helping them understand which pages they are allowed to crawl and which ones are restricted.
For example, if you don’t want search engines to index certain areas of your website like private directories or duplicate content, the robots.txt file can specify those instructions.
Why Do You Need Robots.txt?
While some parts of your website should be accessible to search engines for ranking and visibility, there are instances where you might want to prevent crawlers from accessing specific pages. Here’s why robots.txt is crucial:
- Preventing Duplicate Content: Blocking sections of your website with identical content can help avoid duplicate indexing.
- Enhancing Crawl Efficiency: Search engines have a limited crawl budget, so restricting access to unnecessary pages (like admin areas) can help them focus on your valuable content.
- Protecting Sensitive Information: If you have sections like staging environments or sensitive files that shouldn’t be indexed, robots.txt helps keep them hidden from search engines.
Setting Up Robots.txt
Setting up a robots.txt file is simpler than you might think. Follow these steps:
- Create a Text File: Open any text editor (such as Notepad or TextEdit) and create a new file named robots.txt. Ensure the file uses plain text format.
- Basic Syntax:
- User-agent: Refers to the specific search engine or bot you want to address (e.g., Googlebot).
- Disallow: This directive tells the bot which pages or directories not to crawl.
- Allow: Used when you want to allow bots to crawl specific pages or directories within a restricted area.
- Sitemap: Optionally, you can specify the location of your XML sitemap.
Example:
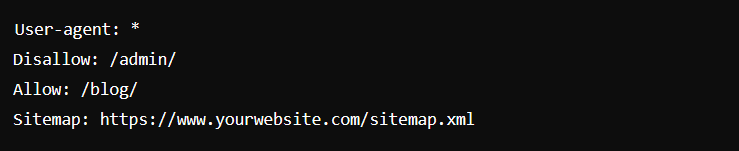
This example allows all search engines (*) to crawl everything except the /admin/ directory while ensuring that the /blog/ directory is fully accessible.
- Upload the File: Once you’ve created the robots.txt file, upload it to the root directory of your website. The URL should be accessible at https://www.yourwebsite.com/robots.txt.
Best Practices for Using Robots.txt
To ensure the effective use of your robots.txt file, here are some best practices to follow:
Avoid Blocking Critical Resources: Ensure you don’t accidentally block essential resources like CSS and JavaScript files, as this could impact how search engines understand and index your website.
Use Robots.txt for Non-Sensitive Data: Remember that robots.txt is only a suggestion to bots. Some malicious crawlers might still ignore the file. For sensitive information, use password protection or noindex meta tags instead.
Test Your Robots.txt File: Before going live, test your robots.txt file using Google’s Robots Testing Tool. This ensures you don’t inadvertently block important content from being indexed.
Specify Sitemap Location: Including your sitemap in the robots.txt file helps crawlers discover all the pages on your site, improving the chances of proper indexing.
Common Use Cases for Robots.txt
1. Blocking Admin Pages: If you run a website with an admin area, it’s good practice to disallow search engine crawlers from indexing those pages.

2. Preventing Crawling of Duplicate Content: If your website has multiple URLs leading to the same content (such as sorting filters in e-commerce), disallow crawlers from accessing those URLs to avoid duplicate content issues.

3. Allowing Crawlers to Access Subdirectories: If you block a directory but want to allow a specific subdirectory, you can explicitly allow access

Conclusion
The robots.txt file is a powerful tool that gives you control over what search engines can and cannot index on your website. By using it wisely, you can protect sensitive areas, avoid duplicate content, and ensure search engines crawl the most important parts of your site. Just remember to test your robots.txt file before going live and stay updated with any changes in search engine behavior. Now, go ahead and give your website the optimization it deserves by setting up a well-structured robots.txt file!